




The research carried out within CORECON is based on a large database that consists of hundreds of news articles and social media entries in Romanian, Polish and English. These constitute a corpus (plural: corpora): a large set of linguistic data (e.g., collected from news outlets and social media) that can be processed with the use of quantitative or qualitative methods. Corpora may be used in various types of research: from a large-scale study that examines general properties of language, to a small study based on a set of comments collected from a post by Newsweek on Facebook. Corpora can get fairly large: for instance, the Polish corpus we have built for CORECON currently contains 1.4 million words and is still growing.
Corpora are usually built with a particular research question in mind. In some cases, a corpus can be comprehensive, encompassing all texts that researchers are interested in. For instance, a study interested in the style of William Shakespeare could, with relative ease, collect all his plays. In other cases, the size of available data is so vast that it is impossible to gather everything; e.g., the existing news content on a given topic is usually far too extensive to be obtainable in full. In such cases, the texts are sampled and only smaller sections of the available data are included. A good practice is to develop a consistent, objectivised approach to data collection: an algorithm of sorts that ensures that the data represent a given phenomenon to a relevant extent.
In terms of corpus building, data can be obtained either manually or through scraping; the choice of method depends on the availability of the data and the desired contents of the corpus itself. Scraping automates the process, employing special programs to harvest data directly from access points or by simulating human interaction with the web. This makes it possible to obtain enormous amounts of data, but due to how scraping works, corpora collected this way are likely to contain irrelevant entries, contaminated data and repeated items. This of course means that additional steps need to be taken to clean up the data after collection and ensure their validity. At the same time, scraping is no longer as easy as it used to be, since many news outlets and social media block or explicitly ban this form of data collection. Manual collection, while tedious and time-consuming, means that the resulting corpus is more reliably usable, as the researchers have full knowledge of and control over its contents.
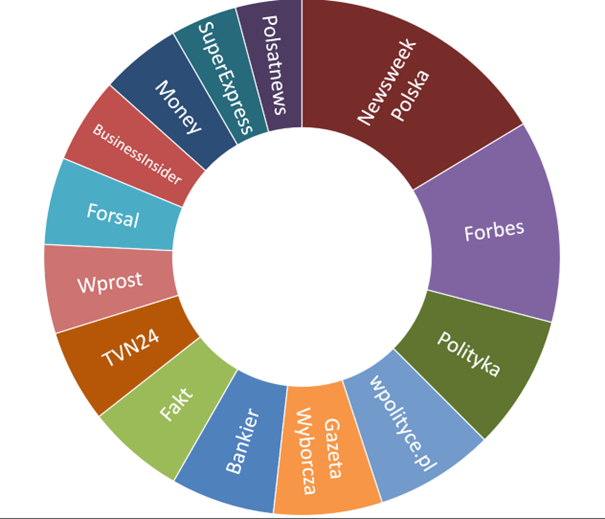
When building the CORECON corpus, we have employed both the approaches: the Romanian and Polish components have been collected manually (as these constitute focal points of our studies), while the English corpus has been scraped (to serve as a point of reference in our investigations). Our study examines the media contexts surrounding the war in Ukraine and so the amount of available data is simply too vast: for that reason, we selected the data from most influential media outlets in Polish (see figure below) and Romanian, with 5 war-related articles per outlet per month, starting from February 2022 until June 2024 (with the remaining data for 2024 to be collected in early 2025). The corpus was compiled to encompass as many contexts as possible, focusing on the military, political, social and economic issues pertinent to the conflict. This was substituted by selected social media texts. All these records (available at: https://corecon.omeka.net/) now serve as a point of reference or even the main resource of our analyses. The corpus constitutes a meaningfully large resource that allows our researchers to pursue their chosen topics and investigate a wide variety of linguistic features from their preferred angles. The Polish corpus, the contents of which are presented below, contains articles from a wide array of Polish media, including tabloids (SuperExpress and Fakt); periodicals (Newsweek, Polityka, Wprost, wpolityce.pl); newspapers (Gazeta Wyborcza); news stations (TVN24, Polsat News); popular web portals (onet.pl); and business-economic media (Business Insider, Forbes, Bankier, Forsal, Money.pl). Efforts were made to include outlets that represent the centre (e.g., Newsweek), as well as more right- (e.g. wpolityce.pl) and left-leaning (e.g. Gazeta Wyborcza) media. The data have been consistently collected from them based on the above-described principle, even though the average sizes of individual articles they publish vary. This means that for comparisons between individual newspapers, the data might need to be normalised, rather than analysed as raw frequencies (more about this in my next blog post!).
The collected texts are usually stored as databases. Each text, being a database entry, requires appropriate description, or metadata, so that it is easily identifiable; some elements of such descriptions do also allow to filter and process data more efficiently. For example, if the metadata include date of publication of news items and the corpus entries are gathered based on a fixed procedure, enough of such entries might allow the researcher to carry out a diachronic analysis, examining how certain trends develop over time. If the news outlets themselves are included into the metadata, filtering the data by source might allow the researchers to examine smaller sets of more specific texts instead.
In the case of the CORECON corpus, we have accounted for publication dates, allowing us to track the use of specific contrasting lexical items, phrases and even sentiment throughout the war. We have also categorised each corpus entry based on the journalism genres it belongs to (report, feature, interview, advocacy, social media post, other). Finally, we broke the texts down into two large categories: socio-economic and political-military texts. This allows for more fine-grained studies to easily extract particular texts and explore them as separate, smaller subcorpora (e.g., a study that focuses on the discourse around the economic impact of migrants might not want to consider the data related to the military side of the operations). The headlines have also been extracted as separate metadata entries and can now be analysed at their own right while remaining in the context of their respective articles.
Corpora may also be further annotated, including additional information or interpretation of the texts or specific passages, as well as distinguishing linguistic variables. Annotation heavily depends on corpus size and type. Smaller corpora will usually be examined through qualitative means and their annotation will be done manually, often reflecting the researcher’s interpretation or classification of their content. Larger corpora might include automatic or semi-automatic annotation of their grammar (parts of speech, inflections, parts of sentence) or simple semantic and pragmatic properties (e.g., sentiment and speech acts). All this depends on the needs of the particular study at hand.
Feel free to check our existing conference presentations to see how we have employed our corpus in research (Conferences tab of https://grants.ulbsibiu.ro/corecon/results/). Stay tuned for future posts to learn how to analyse corpus data, what tools to use and how to make sense of the results!
Text by Jędrzej Olejniczak
corpus linguistics corpus compilation